决策树是一类常见的机器学习方法,我们通过树状的结构进行分类最终得到决策。一般的,一棵决策树包含一个根结点、若干个内部结点和若干个叶结点。
叶结点对应于决策结果,其他每个结点则对应于一个属性测试;
每个结点包含的样本集合根据属性测试的结果被划分到子结点中;
根结点包含样本全集,从根结点到每个叶结点的路径对应了一个判定测试序列;
决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树,其基本流程遵循简单且直观的“分而治之”(divide-and-conquer)策略。
基本流程
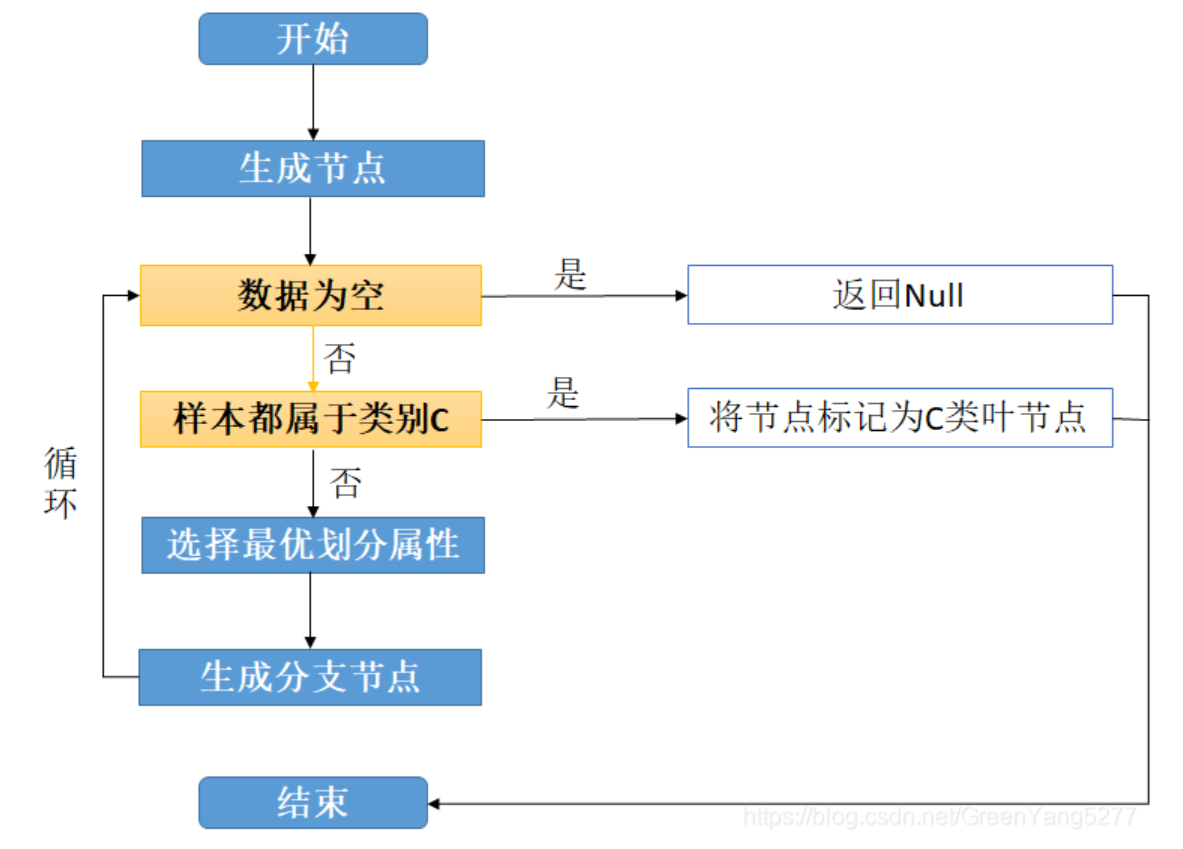
- 显然,决策树的生成是一个递归过程.在决策树基本算法中,有三种情形会导致递归返回:
- 当前结点包含的样本全属于同一类别,无需划分;
- 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分;
- 当前结点包含的样本集合为空,不能划分
- 第二种情形下,我们把当前结点标记为叶结点,并将其类别设定为该结点所含样本最多的类别;
- 第三种情形下,同样把当前结点标记为叶结点,但将其类别设定为其父结点所含样本最多的类别
- 注意这两种情形的处理实质不同
- 第二种是在利用当前结点的后验分布
- 第三种则是把父结点的样本分布作为当前结点的先验分布
- 注意这两种情形的处理实质不同
划分选择
决策树学习的关键是如何选择最优划分属性。一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样 本尽可能属于同一类别,即结点的“纯度”(purity)越来越高。
信息增益
文档信息
- 本文作者:Yizhuo Zheng
- 本文链接:https://amark071.github.io/learnai//2024/08/14/decision-tree/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)