QQQ量化中GEMM算子的研究
在自然语言处理领域,大型语言模型(LLM)在自然语言处理领域的应用越来越广泛。然而,随着模型规模的增大,计算和存储资源的需求也急剧增加。为了降低计算和存储开销,同时保持模型的性能,LLM大模型的量化技术应运而生。LLM大模型的量化技术主要是通过对模型参数进行压缩和量化,从而降低模型的存储和计算复杂度。具体来说如下:
- 参数压缩:通过将模型中的浮点数参数转换为低精度的整数参数,量化技术可以实现参数的压缩。这不仅可以减少模型所需的存储空间,还可以降低模型加载的时间。
- 计算加速:由于低精度整数运算的速度远快于浮点数运算,量化技术还可以通过降低计算复杂度来实现计算加速。这可以在保证模型性能的同时,提高模型的推理速度。
- 量化技术的三个主要目的:节省显存、加速计算、降低通讯量。
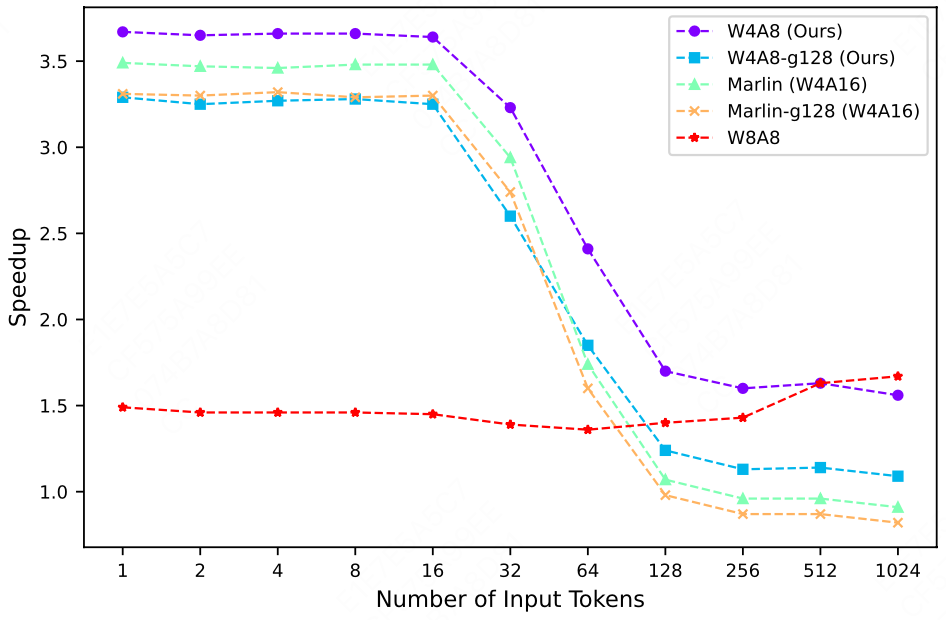
QQQ量化的流程与效果
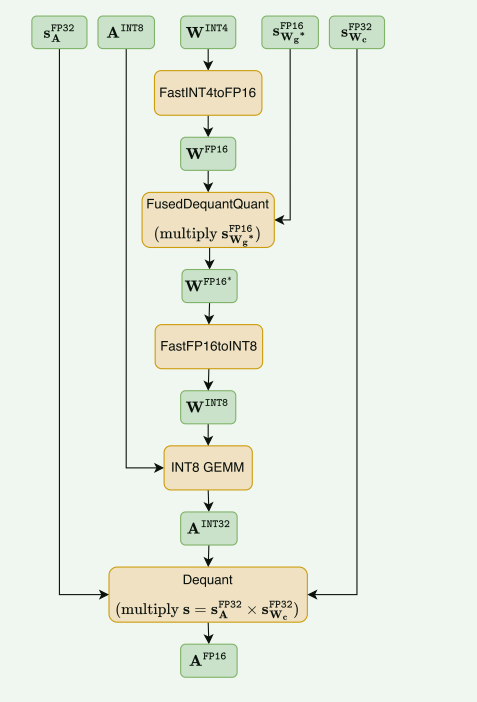
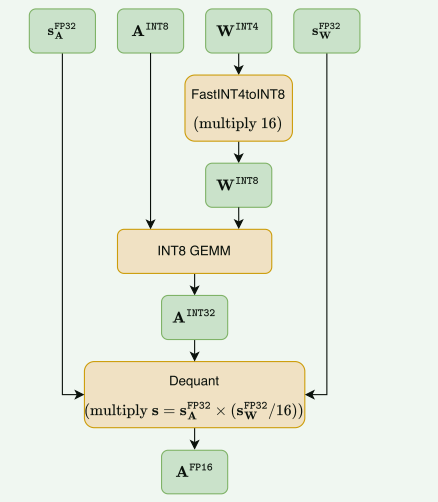
- 参数解析:绿色的是数据,橙色的操作,A:激活;W:权重;s:量化粒度
QQQ_GEMM算子代码分析
ceildiv函数
- 功能:返回值为a/b 向上取整
constexpr int ceildiv(int a, int b) {return (a + b - 1) / b;}
Vec结构
- 这个 Vec 结构体提供了一个轻量级的、固定大小的向量抽象,可用于 GPU 加速的计算中。固定大小允许编译器优化内存布局和访问模式对 GPU 性能很重要。
template <typename T, int n>
struct Vec {
T elems[n];
__device__ T& operator[](int i) {
return elems[i];
}
};
//这个 Vec 结构体包含以下成员:
//T elems[n]: 这是一个大小为 n 的静态数组,用于存储向量中的元素。数组元素的类型由 T 指定。
//__device__ T& operator[](int i): 这是一个重载的下标运算符 []。它允许你使用索引访问向量中的元素
//__device__ 关键字表明这个函数是为 GPU 设备设计的,可能是 CUDA 或 OpenCL 程序的一部分。
//下面是一个使用 Vec 结构体的例子:
// Vec<float, 3> v;
// v[0] = 1.0f;
// v[1] = 2.0f;
// v[2] = 3.0f;
using I4 = Vec<int, 4>;
using FragA = Vec<uint32_t, 2>;
using FragB = Vec<uint32_t, 1>;
using FragC = Vec<int, 4>;
using FragS_GROUP = Vec<half2, 1>; // weight per-group quantization scales
using FragS_CHANNEL = Vec<float, 2>; // weight per-channel quantization scales or activaton per-token quantization scales
// using用法为我们的结构体定义了别名
汇编操作
- asm: 这是 C/C++ 中内联汇编的关键字,用于在高级语言代码中嵌入汇编指令。
- volatile: 这个关键字告诉编译器不要优化或重排这段汇编代码,确保它按照程序员的预期执行。
异步内存拷贝
__device__ inline void cp_async4_pred(void* smem_ptr, const void* glob_ptr, bool pred = true) {
const int BYTES = 16;
uint32_t smem = static_cast<uint32_t>(__cvta_generic_to_shared(smem_ptr));
asm volatile(
"{\n"
" .reg .pred p;\n"
" setp.ne.b32 p, %0, 0;\n"
" @p cp.async.cg.shared.global [%1], [%2], %3;\n"
"}\n" :: "r"((int) pred), "r"(smem), "l"(glob_ptr), "n"(BYTES)
);
}
//smem_ptr: 指向共享内存的指针;glob_ptr: 指向全局内存的指针;pred: 一个可选的布尔参数,默认为 true
//共享内存地址计算:uint32_t smem = static_cast<uint32_t>(__cvta_generic_to_shared(smem_ptr));
//使用内置函数 __cvta_generic_to_shared 将 smem_ptr 转换为共享内存地址,并存储在 smem 变量中。
//".reg .pred p;"在内联汇编中声明了一个名为 p 的布尔型寄存器。
//判断条件计算:"setp.ne.b32 p, %0, 0;"将 pred 参数的值与 0 进行比较,结果存储在寄存器 p 中。
//异步复制操作:"@p cp.async.cg.shared.global [%1], [%2], %3;"如果 p 寄存器为真(即 pred 为真),则执行异步的共享内存到全局内存的复制操作。
//所以总结起来,这个函数的作用就是从全局内存的 glob_ptr 地址,异步拷贝 16 个字节的数据到共享内存的 smem_ptr 地址。这种异步拷贝方式可以提高 GPU 计算的效率。
__device__ inline void cp_async4(void* smem_ptr, const void* glob_ptr) {
const int BYTES = 16;
uint32_t smem = static_cast<uint32_t>(__cvta_generic_to_shared(smem_ptr));
asm volatile(
"{\n"
" cp.async.cg.shared.global [%0], [%1], %2;\n"
"}\n" ::"r"(smem),
"l"(glob_ptr), "n"(BYTES));
}
__device__ inline void cp_async1(void* smem_ptr, const void* glob_ptr) {
const int BYTES = 4;
uint32_t smem = static_cast<uint32_t>(__cvta_generic_to_shared(smem_ptr));
asm volatile(
"{\n"
" cp.async.ca.shared.global [%0], [%1], %2;\n"
"}\n" ::"r"(smem),
"l"(glob_ptr), "n"(BYTES));
}
__device__ inline void cp_async_fence() {
asm volatile("cp.async.commit_group;\n" ::);
}
//cp.async.commit_group是一个 CUDA 指令,用于提交一组异步内存拷贝任务,确保它们后续能够并行执行。
//调用这个函数可以确保之前的异步拷贝任务已经全部提交完成,可以进行后续的计算操作。
template <int n>
__device__ inline void cp_async_wait() {
asm volatile("cp.async.wait_group %0;\n" :: "n"(n));
}
//该函数使用内联汇编执行cp.async.wait_group %0` 指令,其中 `%0` 会被替换成传入的 `n` 参数。
//cp.async.wait_group是一个 CUDA 指令,用于等待最多 `n` 个异步拷贝任务完成。
//调用这个函数可以确保之前提交的异步拷贝任务已经全部完成,再进行后续的计算。
矩阵计算
__device__ inline void mma(const FragA& a_frag, const FragB& frag_b, FragC& frag_c) {
const uint32_t* a = reinterpret_cast<const uint32_t*>(&a_frag);
const uint32_t* b = reinterpret_cast<const uint32_t*>(&frag_b);
int* c = reinterpret_cast<int*>(&frag_c);
//将 a_frag 的地址转换为 32 位无符号整数指针 a。这样可以方便地访问 a_frag 的数据
asm volatile(
"mma.sync.aligned.m16n8k16.row.col.satfinite.s32.s8.s8.s32 "
"{ %0,%1,%2,%3}, { %4,%5}, { %6}, { %7,%8,%9,%10};\n"
: "=r"(c[0]), "=r"(c[1]), "=r"(c[2]), "=r"(c[3])
: "r"(a[0]), "r"(a[1]), "r"(b[0]),
"r"(c[0]), "r"(c[1]), "r"(c[2]), "r"(c[3])
);
}
// sync: 同步执行
// aligned: 内存地址对齐
// m16n8k16: 输入矩阵 A 的大小为 16x8,输入矩阵 B 的大小为 8x16
// row.col: 输入矩阵 A 的布局为行主序,输入矩阵 B 的布局为列主序
// satfinite: 输出结果进行饱和截断
// s32.s8.s8.s32: 输入数据类型为 8 位有符号整数,输出数据类型为 32 位有符号整数
// 第一个 s32 表示输出矩阵 C 的数据类型
// 第二个 s8 表示输入矩阵 A 的数据类型
// 第三个 s8 表示输入矩阵 B 的数据类型
// 第四个 s32 表示累加器的数据类型
// 这种固定的数据类型声明顺序是 CUDA 矩阵乘法指令的一种标准写法,可以让硬件更好地识别和执行这种计算操作。
__device__ inline void ldsm4(FragA& frag_a, const void* smem_ptr) {
uint32_t* a = reinterpret_cast<uint32_t*>(&frag_a);
uint32_t smem = static_cast<uint32_t>(__cvta_generic_to_shared(smem_ptr));
asm volatile(
"ldmatrix.sync.aligned.m8n8.x2.shared.b16 { %0,%1}, [%2];\n"
: "=r"(a[0]), "=r"(a[1]) : "r"(smem)
);
}
//ldsm4 函数是用于从共享内存加载数据到一个名为 FragA 的数据结构中
类型转换
inline __device__ half2 float2_to_half2(float2 f) {
uint32_t res;
uint16_t h0, h1;
asm volatile("cvt.rn.f16.f32 %0, %1;\n" : "=h"(h0) : "f"(f.x));
asm volatile("cvt.rn.f16.f32 %0, %1;\n" : "=h"(h1) : "f"(f.y));
asm volatile("mov.b32 %0, { %1, %2};\n" : "=r"(res) : "h"(h0), "h"(h1));
return reinterpret_cast<half2&>(res);
}
inline __device__ float int32_to_float(int h) {
float res;
asm volatile("cvt.rn.f32.s32 %0, %1;\n" : "=f"(res) : "r"(h));
return res;
}
// Efficiently dequantize an int32 value into a full B-fragment of 4 int8 values for weight per channel dequant.
__device__ inline FragB dequant_per_channel(int q) {
static constexpr int MASK = 0xf0f0f0f0;
FragB frag_b;
frag_b[0] = (q & MASK);
return frag_b;
}
反量化操作(还需研究)
- lop3.b32指令详见:lop3.b32命令的含义研究
template <int lut>
__device__ inline uint32_t lop3(uint32_t a, uint32_t b, uint32_t c) {
uint32_t res;
asm volatile(
"lop3.b32 %0, %1, %2, %3, %4;\n"
: "=r"(res) : "r"(a), "r"(b), "r"(c), "n"(lut)
);
return res;
}
__device__ inline FragB dequant_per_group(int q, FragS_GROUP& frag_s, int i) {
// convert 4 int8 to 4 half
static constexpr uint32_t LO = 0x000f000f;//提取int8中低4位
static constexpr uint32_t HI = 0x00f000f0;//提取int8中高4位
static constexpr uint32_t EX = 0x64006400;//一个常数
// Guarantee that the `(a & b) | c` operations are LOP3s.
uint32_t t0 = lop3<(0xf0 & 0xcc) | 0xaa>(q, LO, EX);
uint32_t t1 = lop3<(0xf0 & 0xcc) | 0xaa>(q, HI, EX);
// We want signed int4 outputs, hence we fuse the `-8` symmetric zero point directly into `SUB` and `ADD`.
static constexpr uint32_t SUB = 0x64086408;
static constexpr uint32_t MUL = 0x2c002c00;
static constexpr uint32_t ADD = 0xd480d480;
*reinterpret_cast<half2*>(&t0) = __hsub2(
*reinterpret_cast<half2*>(&t0),
*reinterpret_cast<const half2*>(&SUB)
);
*reinterpret_cast<half2*>(&t1) = __hfma2(
*reinterpret_cast<half2*>(&t1),
*reinterpret_cast<const half2*>(&MUL), *reinterpret_cast<const half2*>(&ADD)
);
//使用CUDA内置的函数_hsub2和_hfma2对t0和t1进行反量化运算
uint16_t s = reinterpret_cast<uint16_t*>(&frag_s)[i];
uint32_t double_s;
// pack 2xfp16 to half2
asm volatile("mov.b32 %0, { %1, %2};\n" : "=r"(double_s) : "h"(s), "h"(s));
//从输入片段 frag_s 中读取一个 uint16 值,存储在 s 变量中。
//定义了一个 double_s 变量,并使用内联汇编指令将两个 s 值打包成一个 half2 数据。
// dequant and convert 4 half to 4 uint8 (be placed at the low 8 bits of 4 half, respectively)
static constexpr uint32_t MAGIC_NUM = 0x64806480;
*reinterpret_cast<half2*>(&t0) = __hfma2(
*reinterpret_cast<half2*>(&t0),
*reinterpret_cast<half2*>(&double_s), *reinterpret_cast<const half2*>(&MAGIC_NUM)
);
*reinterpret_cast<half2*>(&t1) = __hfma2(
*reinterpret_cast<half2*>(&t1),
*reinterpret_cast<half2*>(&double_s), *reinterpret_cast<const half2*>(&MAGIC_NUM)
);
//使用 __hfma2 函数,将 t0 和 t1 中的 half2 数据分别与 double_s 和 MAGIC_NUM 相乘并相加,结果存回 t0 和 t1。这些操作可能是为了将 half 数据转换为 uint8 数据的中间步骤
// take out the 4 uint8 from 4 half, then convert them to 4 int8 and pack 4 int8 into 1 uint32
FragB frag_b;
uint32_t uint8s;
static constexpr uint32_t MASK_0246 = 0x6420;
static constexpr uint32_t UINT8s_TO_INT8s_MASK = 0x80808080;
asm volatile("prmt.b32 %0,%1,%2,%3;\n" : "=r"(uint8s) : "r"(t0), "r"(t1), "n"(MASK_0246));
frag_b[0] = (uint8s ^ UINT8s_TO_INT8s_MASK);
return frag_b;
//定义了一个输出片段 frag_b 和一个中间变量 uint8s。
//定义了两个常量:MASK_0246: 可能是用于从 half 数据中提取 uint8 数据的掩码。UINT8s_TO_INT8s_MASK: 可能是用于将 uint8 数据转换为 int8 数据的掩码。
//使用内联汇编指令 prmt.b32 从 t0 和 t1 中提取 uint8 数据,存储在 uint8s 中。将 uint8s 与 UINT8s_TO_INT8s_MASK 进行异或操作,得到 int8 数据,存储在输出片段 frag_b[0] 中。最后返回输出片段 frag_b。
}
并发同步
- 这段代码实现了一个基于 CUDA 的同步机制,使用一个共享的计数器(
lock)来协调线程块之间的同步。barrier_acquire()函数确保在所有线程达到指定的计数器值之前,不会有任何线程继续执行。barrier_release()函数在一个线程块完成任务后,释放同步屏障并更新计数器。这种同步机制可以用于在 CUDA 程序中实现复杂的并行计算。
__device__ inline void barrier_acquire(int* lock, int count) {
//lock: 一个指向整型的指针,用于实现同步屏障。count: 表示需要等待的线程数。
if (threadIdx.x == 0) {
int state = -1;
do
asm volatile ("ld.global.acquire.gpu.b32 %0, [%1];\n" : "=r"(state) : "l"(lock));
while (state != count);
}
//如果当前线程是线程块中的第一个线程(threadIdx.x == 0),则执行以下操作:
//初始化 state 变量为 -1。
//使用 ld.global.acquire.gpu.b32 指令从 lock 指针中读取值,并存储在 state 中。这个指令确保后续写入操作对全局内存可见。
//使用 do-while 循环,直到 state 的值等于 count。
__syncthreads();
//执行 __syncthreads() 指令,确保所有线程都已执行到这一步。
}
__device__ inline void barrier_release(int* lock, bool reset = false) {
//lock: 一个指向整型的指针,用于实现同步屏障。reset: 一个可选参数,用于指示是否重置 lock 指针指向的值。
__syncthreads();
if (threadIdx.x == 0) {
if (reset) {
lock[0] = 0;
return;
}
int val = 1;
// Make sure that all writes since acquiring this barrier are visible globally, while releasing the barrier.
asm volatile ("fence.acq_rel.gpu;\n");
asm volatile ("red.relaxed.gpu.global.add.s32 [%0], %1;\n" : : "l"(lock), "r"(val));
}
//首先执行 __syncthreads() 指令,确保所有线程都已执行到这一步。
//如果当前线程是线程块中的第一个线程(threadIdx.x == 0),则执行以下操作:
//如果 reset 参数为 true,则将 lock[0] 设置为 0,并返回。
//如果 reset 参数为 false,则将整数 1 存储在 val 变量中。
//执行 fence.acq_rel.gpu 指令,确保在释放同步屏障之前,所有写入操作都对全局内存可见。
//执行 red.relaxed.gpu.global.add.s32 指令,将 val 的值(1)添加到 lock 指针指向的全局内存位置。这将释放同步屏障,并增加计数器的值。
}
矩阵乘法算子
template <
const int threads, // number of threads in a threadblock
const int thread_m_blocks, // number of 16x16 blocks in the m dimension (batchsize) of the threadblock
const int thread_n_blocks, // same for n dimension (output)
const int thread_k_blocks, // same for k dimension (reduction)
const int stages, // number of stages for the async global->shared fetch pipeline
const int group_blocks = -1 // number of consecutive 16x16 blocks with a separate quantization scale
>
__global__ void Marlin(
const int4* __restrict__ A, // int8 input matrix of shape mxk
const int4* __restrict__ B, // 4bit quantized weight matrix of shape kxn
int4* __restrict__ C, // int32 global_reduce buffer of shape (max_par*16*4)xn , as int8 tensor core's output is int32 dtype
int4* __restrict__ D, // fp16 output buffer of shape mxn
const float* __restrict__ s1, // fp32 activation per-token quantization scales of shape mx1
const int4* __restrict__ s2, // fp32 weight per-channel quantization scales of shape 1xn
const int4* __restrict__ s3, // fp16 weight per-group quantization scales of shape (k/groupsize)xn, when group_blocks=-1, it should be nullptr
int prob_m, // batch dimension m
int prob_n, // output dimension n
int prob_k, // reduction dimension k
int* locks // extra global storage for barrier synchronization
)
文档信息
- 本文作者:Yizhuo Zheng
- 本文链接:https://amark071.github.io/learnai//2024/08/19/qqq-gemm/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)