快速反量化运算
(论文中只量化了权重,和最后目的W4->W8接近)主要学习了fast int8 to fp16
float16的存储原理与性质
- 存储浮点数我们主要有以下三个部分组成(以fp16为例子的话)
- 符号位(1bit)
- 指数位(5bit)
- 位数位(10bit)
- 转换公式为:
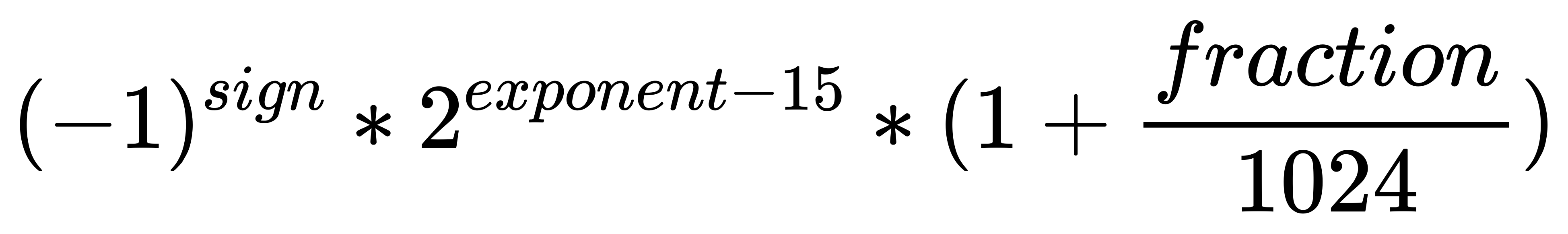
性质一:对于不小于1024但小于2048的X,我们将其1024的部分准确的存储在指数部分中,而int(X-1024)部分被存储在尾数部分中(完全来自于只有10位的尾数导致了fraction要除以的数只有1024)
- 性质二:对于小于1024的自然数Y,我们通过Y+1024的FP16表示将Y存储在了加上了1024的浮点数的尾数当中
- 加法这个步骤我们可以通过 0x6400 or Y来实现
- 优点:可以通过内联汇编,调用了PRMT和SUB.F16进行反量化,而不是直接static_cast<>(数值转换指令的吞吐是比较低的,而数值运算和位运算的指令吞吐则要高很多)。
// Lastly, we subtract 1152 from our constructed number using fp16 math to get our signed integer as fp16.
static constexpr uint32_t I8s_TO_F16s_MAGIC_NUM = 0x64806480;
asm volatile("sub.f16x2 %0, %1, %2;\n" : "=r"(h[0]) : "r"(h[0]), "r"(I8s_TO_F16s_MAGIC_NUM));
asm volatile("sub.f16x2 %0, %1, %2;\n" : "=r"(h[1]) : "r"(h[1]), "r"(I8s_TO_F16s_MAGIC_NUM));
- 这两行代码使用了内联汇编,执行一个浮点数的减法操作:
- sub.f16x2 是指进行浮点16位的减法。
- %0 是目标寄存器,表示要存储结果的地方(h[0/1])。
- %1 是第一个操作数(h[0/1])。
- %2 是第二个操作数(I8s_TO_F16s_MAGIC_NUM)。
- 这段代码的意思是将 h[0/1] 减去 I8s_TO_F16s_MAGIC_NUM,并将结果存储回 h[0/1]。
- 为什么是减去1152(即0x6480)?
- 为了int8的零点偏移(做成了一个无符号的整型所以之前加了128)
pmrt命令详解
- 语法:
prmt.b32{.mode} d, a, b, c; .mode = { .f4e, .b4e, .rc8, .ecl, .ecr, .rc16 } - PRMT指令,会从两个32位寄存器a, b中选取四个任意字节,重新组成32位值,并保存在目标寄存器中。
- 在通用形式(未指定模式)中最终选取的4个字节,由四个4bit的选择器组成。PRMT指令会将两个源寄存器a,b中的字节编号为0到7,即为b0~b7
- 对于目标寄存器中的每个字节(一共4bytes),定义了一个4位选择器。
- 选择值的3个低位lsb指定应将8个源字节中的哪一个移至目标中位置。
- msb定义是否应直接复制原始字节值,或者是否应复制符号(即,是否进行符号扩展)
- msb=0,表示直接复制原始的bit值
- msb=1,表示进行符号扩展
- 为简单起见,这里只关注PRMT指令的通用形式。(事实上,这个指令还有f2e、b4e、rc8等特殊模型)
- 以上述语法为例:
prmt.b32 d,a,b,c;- a,b为32bit的源操作数;c为选择器;d为目标操作数
- 注意:c只有最低的16位有用
- 因为d只能有4个字节,每个字节只需要一个4bit的选择值即可(因为3位的二进制数可以表示0~7)
- 假设我们要确定d的最低位字节d.b0,于是我们查看c对应的值(从c[0]~c[3]),假设为0001
- 于是有msb=0;lsb=001(转化为10进制为1)
- 表示不进行符号扩展,且选择b1作为d.b0的值
- 类似的有:c[4]~c[7]->d.b1;c[8]~c[11]->d.b2;c[12]~c[15]->d.b3
- 因为d只能有4个字节,每个字节只需要一个4bit的选择值即可(因为3位的二进制数可以表示0~7)
uint32_t* h = reinterpret_cast<uint32_t*>(&result);
uint32_t const i8s = reinterpret_cast<uint32_t const &>(source);
//step1 加载4个int8的值[e0,e1,e2,e3]
static constexpr uint32_t mask_for_elt_01 = 0x5250;
static constexpr uint32_t mask_for_elt_23 = 0x5351;
static constexpr uint32_t start_byte_for_fp16 = 0x64646464;
asm volatile("prmt.b32 %0,%1,%2,%3;\n" : "=r"(h[0]) : "r"(i8s), "n"(start_byte_for_fp16), "n"(mask_for_elt_01));
asm volatile("prmt.b32 %0,%1,%2,%3;\n" : "=r"(h[1]) : "r"(i8s), "n"(start_byte_for_fp16), "n"(mask_for_elt_23));
//step2 创建第2个32bit寄存器R1存储[e0+1024,e1+1024]的fp16的表示
//创建第2个32bit寄存器R1存储[e2+1024,e3+1024]的fp16的表示
static constexpr uint32_t I8s_TO_F16s_MAGIC_NUM = 0x64806480;
asm volatile("sub.f16x2 %0, %1, %2;\n" : "=r"(h[0]) : "r"(h[0]), "r"(I8s_TO_F16s_MAGIC_NUM));
asm volatile("sub.f16x2 %0, %1, %2;\n" : "=r"(h[1]) : "r"(h[1]), "r"(I8s_TO_F16s_MAGIC_NUM));
//step3 做减法减去1152,最后得到了两个寄存器用来存放转化为fp16的4个e
文档信息
- 本文作者:Yizhuo Zheng
- 本文链接:https://amark071.github.io/learnai//2024/09/03/dequantize/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)