OpenMP语法与使用
OpenMP语法与使用简介什么是OpenMPFork-Join模式OpenMP API的三个要素最小侵害性质OpenMP 关键语法与概念列表OpenMP 语法详解程序编译获取线程与计时设置与获取线程线程数的相关问题获取时钟时间并行区制导语句并行区构造:parallel循环工作构造:forfor循环构造:用于对循环进行多线程并行执行线程调度其他工作享构造ordered从句与ordered构造collapse从句sections构造single构造任务构造OpenMP任务构造线程控制动态线程嵌套并行flush构造堆栈大小同步构造barrier构造:栅栏同步single构造:有同步master构造:无同步critical构造atomic构造竞争条件和线程安全程序的遗孤持久变量threadprivate 构造全局或静态变量的传递与广播 向量化OpenFOAM的simd构造declare simd构造编译器的自动向量化从句汇总
简介
什么是OpenMP
OpenMP=OpenMulti-Processing 是一种支持共享内存并行的应用开发接口(API)和规范(specification)
支持多种编程语言、指令集架构和操作系统;
由多家计算机厂商组成的非营利组织联合发布;
官方网站: http://www.openmp.org/ (包含了OpenMP相关的接口规范、常见问题等)。
Fork-Join模式
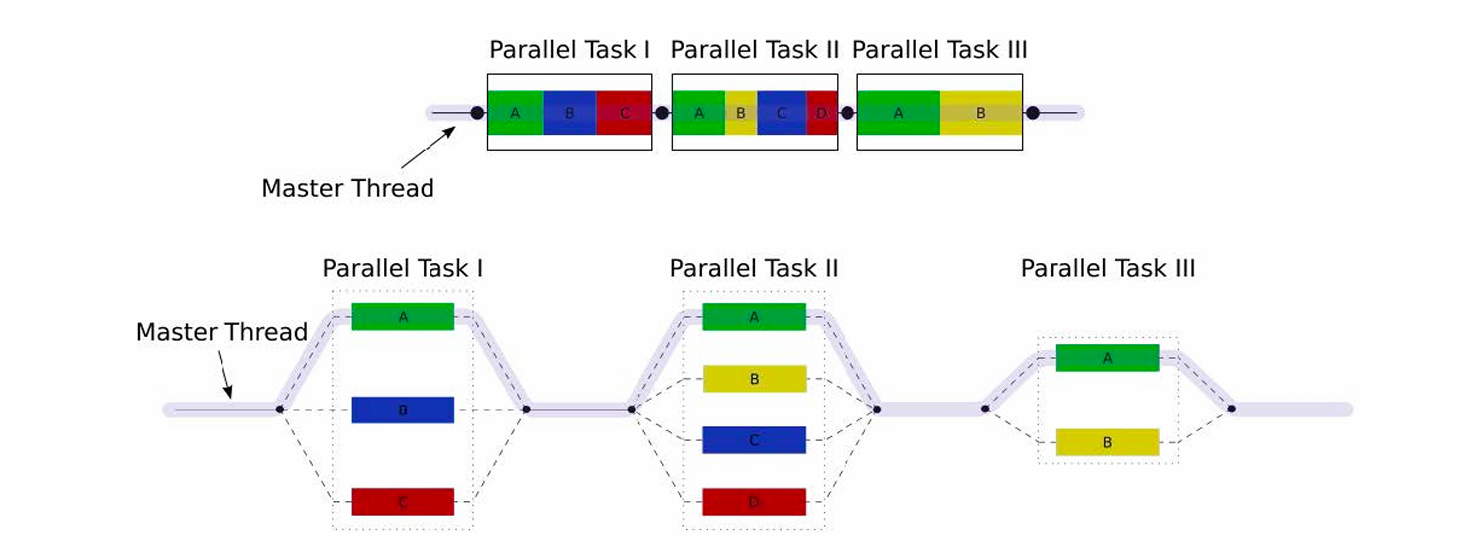
OpenMP主要采用Fork-Join模式进行并行执行;
程序开始时只有一个线程:主线程(masterthread),编号为0。主线程仅当进入并行区(parallel region)才并行执行
Fork:主线程创建一组并行线程,编号0~n-1;
执行:并行线程在并行区中并行执行;
Join:在并行区结尾并行线程进行同步和结束,只保留主线程。
并行区的个数,以及每个并行区中的线程数,都可以任意设置。
OpenMP API的三个要素
运行时库:头文件,库函数的调用和链接
环境变量:运行时控制程序的行为
编译制导软件:在程序中添加一些特殊格式的注释,用于实现功能(若不支持OpenMP则会被忽视)
最小侵害性质
OpenMP提供了内置宏_OPENMP,帮助判断OpenMP是否存在;
借助条件编译,我们可以在不支持OpenMP的环境下也能编译并 正常运行程序
1//omp headerfile3...8..OpenMP 关键语法与概念列表
以下是 OpenMP 主要语法语句的功能简要说明,详细用法会在后面几节中叙述:
#pragma omp parallel创建并行区域,生成一组线程共同执行后续的结构化代码块,线程之间通过交错执行实现并发。omp_set_num_threads()设置程序中 OpenMP 并行区域使用的默认线程数量,通过内部控制变量调整并行规模。omp_get_thread_num()获取当前线程的唯一标识符(ID),常用于 SPMD(单程序多数据)模式下的任务划分。omp_get_num_threads()返回当前并行区域内的总线程数,与线程ID配合实现任务分配逻辑。omp_get_wtime()提供高精度计时功能,用于测量并行代码段的实际执行时间,支持加速比分析和性能问题定位(如虚假共享)。OMP_NUM_THREADS环境变量 通过操作系统环境变量全局控制 OpenMP 程序的默认线程数量(例如export OMP_NUM_THREADS=4)。#pragma omp barrier强制所有线程在代码执行点同步等待,消除竞态条件(race condition)风险。#pragma omp critical定义临界区,确保同一时刻仅有一个线程能执行该代码段,防止数据竞争。#pragma omp for将紧邻的循环任务自动划分给多个线程并行执行(工作共享),需处理循环迭代间的依赖关系。#pragma omp parallel for组合指令:先创建线程组,再将循环任务分配给这些线程并行执行。reduction子句 对指定变量执行多线程归约操作(如求和、求最大值),自动合并各线程的局部结果。schedule(static)静态调度策略:提前将循环迭代块平均分配给线程,适用于均匀计算负载场景。schedule(dynamic)动态调度策略:运行时按需分配迭代块,适用于负载不均衡的循环任务。shared/private/firstprivate控制变量在并行区域内的存储属性:共享内存、线程私有副本、带初始化的私有副本。default(none)要求显式声明所有变量的存储属性,避免因隐式默认规则导致错误。nowait移除并行结构末尾的隐式同步屏障,减少线程等待时间(需手动确保安全性)。#pragma omp single指定代码段仅由单个线程执行,常用于非并行化的初始化或输出操作。#pragma omp task定义可异步执行的任务单元,支持动态任务并行(如递归、不规则算法)。#pragma omp taskwait等待所有已生成的子任务完成,实现任务级同步。
OpenMP 语法详解
程序编译
xxxxxxxxxx31export OMP_NUM_THREADS=4 ##设置环境变量(定义总线程数)2gcc omp_hello.c -o hello -fopenmp -lm ##编译3./hello ##运行获取线程与计时
设置与获取线程
omp_set_num_threads():设置程序中 OpenMP 并行区域使用的默认线程数量,通过内部控制变量调整并行规模。
x
1omp_set_num_threads(4);omp_get_thread_num():获取当前线程的唯一标识符(ID),常用于 SPMD(单程序多数据)模式下的任务划分。omp_get_num_threads():返回当前并行区域内的总线程数,与线程ID配合实现任务分配逻辑。也可通过获取环境变量获得:echo $OMP_NUM_THREADS
xxxxxxxxxx61 2{3 nthreads = omp_get_num_threads();//get num of threads4 tid= omp_get_thread_num();//get my thread id5 printf("From thread %d out of %d, Hello World!\n",tid, nthreads);6}获取曾使用过的最大线程数:int omp_get_max_threads(void)
其可以在任意串行区或并行区使用
按照上述设定:omp_set_num_threads(4),我们有以下输出:
xxxxxxxxxx41From thread 1 out of 4, Hello World!2From thread 0 out of 4, Hello World!3From thread 2 out of 4, Hello World!4From thread 3 out of 4, Hello World!根据上述说明,我们发现我们有两种方式来设置线程数:
通过export OMP_NUM_THREADS=4 直接设置环境变量
通过omp_set_num_threads(4)在程序中设置
线程数的相关问题
如果不设置线程数呢?
OpenMP 默认使用以下规则:
1)默认线程数 = 逻辑 CPU 核心数(例如,4 核 8 线程的 CPU 默认使用 8 线程,i7的是16)。
2)若未设置
OMP_NUM_THREADS环境变量且未调用omp_set_num_threads(),运行时自动分配最大可用线程数。3)验证方法:可通过
unset OMP_NUM_THREADS清除环境变量,程序将完全依赖默认值。
可不可以在并行区内部设置线程数?
通常不能直接生效:
1)并行区域内的线程数在进入时已确定,调用
omp_set_num_threads()不会修改当前区域的线程数。2)例外情况:若开启嵌套并行(设置
OMP_NESTED=TRUE),可在内部并行区域中通过num_threads子句或omp_set_num_threads()修改子区域的线程数。3)建议:在并行区域外部设置全局线程数,或通过
num_threads子句直接指定当前区域的线程数。
如果两种方式设置的不同呢?
优先级顺序(从高到低):
1)if 从句。
2)
num_threads子句(仅影响当前并行区域)。3)
omp_set_num_threads()函数(全局覆盖后续所有并行区域)。4)
OMP_NUM_THREADS环境变量(仅在程序启动时读取)。5)系统默认(一般是可用的处理器核数)。
示例:
1)若环境变量设为
OMP_NUM_THREADS=4,但程序中调用omp_set_num_threads(8),则实际使用 8 线程。2)若同时在
#pragma omp parallel num_threads(2)中指定子句,该区域强制使用 2 线程,其他区域仍用 8 线程。
如果在串行区请求omp_get_num_threads()?
可以,但行为有特定规则:
1)在并行区外调用:返回 0(主线程的默认ID)。
2)在并行区内调用:返回当前线程的ID(0 到
omp_get_num_threads()-1之间的整数)。
为什么只能获取、不能设置线程号?
设计约束与线程管理机制:
1)唯一性与安全性:线程号由OpenMP运行时在创建线程组时自动分配,确保每个线程ID在团队内唯一且连续(0,1,2,…),避免手动设置导致冲突或错误。
2)动态性:线程组可能因动态调度或嵌套并行而动态创建,手动设置线程号会破坏线程间的任务分配逻辑。
3)抽象层封装:OpenMP隐藏了底层线程管理的细节,开发者只需关注任务划分,线程号仅用于区分线程身份。
获取时钟时间
返回当前时钟时间:
xxxxxxxxxx31 t0 = omp_get_wtime();2 ... //dosome works3 t1 = omp_get_wtime()返回时钟刻度:
xxxxxxxxxx11double omp_get_wtick(void)并行区制导语句

OpenMP 制导语句的用法为:
以 #pragma omp 开始;
接着是某一个制导名(directive-name),比如 parallel;
接着是零至多个从句(clause),从句出现的顺序不重要;
注意:如果一行过长,换行时行末需要加“\”。
并行区构造:parallel
用途:划定并行区的范围,并做相关设置
xxxxxxxxxx1 {3 ...4 }控制从句:控制并行区行为
if 从句:决定是否以并行的方式执行并行区
表达式为真(非零):按照并行方式执行并行区;
否则:主线程串行执行并行区;
此从句在每个制导语句中最多仅能出现一次。
num_threads 从句:指定并行区的线程数
此从句在每个制导语句中最多仅能出现一次。
数据域从句:规定数据行为
private从句:指定私有变量列表
每个线程生成一份与该私有变量同类型的数据对象;
声明为私有变量的数据在并行区中都需要重新进行初始化。
shared从句:指定共享变量列表
共享变量在内存中只有一份,所有线程都可以访问;
编程中要确保多个线程访问同一个公有变量时不会有冲突。
default 从句:指定默认变量类型;
shared:默认为共享变量;
none:无默认变量类型,每个变量都需要另外指定。
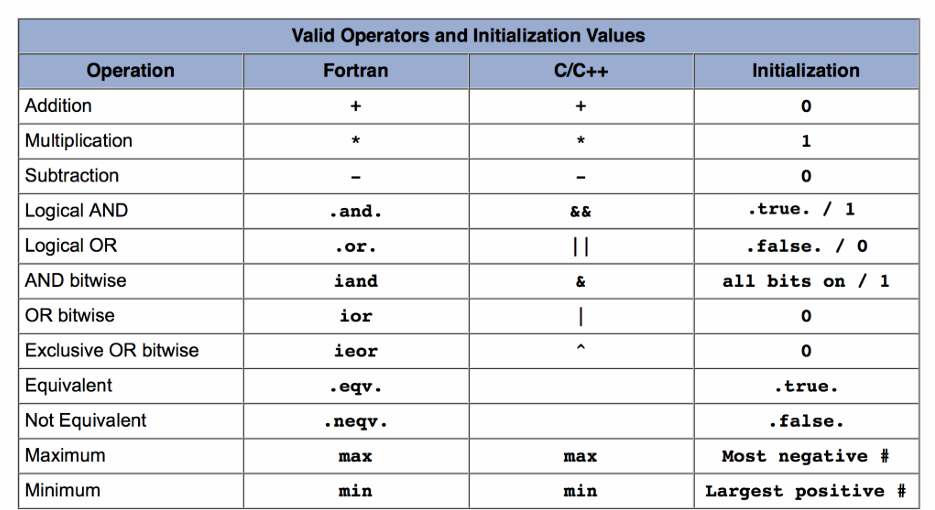
reduction 从句:指定规约变量列表
各个线程对该变量额外进行 operator 定义的规约操作。
#pragma omp parallel reduction(+ : sum):表示当所有线程完成各自的计算后,OpenMP 会自动将每个线程的 sum 副本通过加法操作合并到全局的 sum 变量中。
firstprivate 从句:指定自动初始化的私有变量列表
在并行区执行伊始对该变量根据主线程中的数据进行初始化。
计算例子:计算
x
1int main(int argc, char *argv[]) {6 7 int nthreads, tid, n, i;8 double pi, h, x, t0, t1;9
10 t0 = omp_get_wtime();11 12 n = 10000000;13 h = 1.0 / (double)n;14 pi = 0.0;15
16 17 18 {19 nthreads = omp_get_num_threads();20 tid = omp_get_thread_num();21 for (i = tid + 1; i <= n; i += nthreads) {22 x = h * ((double)i - 0.5);23 pi += 4.0 * h * sqrt(1.0 - x * x);24 }25 }26
27 t1 = omp_get_wtime();28
29 printf("Number of threads = %d\n", nthreads);30 printf("pi is approximately %.16f\n", pi);31 printf("Error is %.16f\n", fabs(pi - PI25DT));32 printf("Wall clock time = %f\n", t1 - t0);33 34 return 0;35}循环工作构造:for
工作共享构造:用于将代码分配采用某种机制给不同的线程执行:循环、分块、单独。
for循环构造:用于对循环进行多线程并行执行
x
1 for (...)3 {4 ...5 }注意:OpenMP的for循环构造对for循环的格式有严格要求:
开始语句:必须是“变量=初值”形式;
终止语句:必须明确变量与边界值的大小关系;
计数语句:必须采用规范的等步长累加或者累减;
不能使用break、goto、return等;
循环变量必须是整数,初值、边界和增量在循环中固定。
线程调度
schedule从句:schedule (type [,chunk])
type:调度类型,包括:
static:静态调度,chunk 大小固定 (默认:n/t);
默认chunk=n/t,按循环起止均匀分配;
调整chunk可以改变静态线程分配的策略。

dynamic:动态调度,chunk 大小固定 (默认:1);
根据线程空闲情况,对工作进行动态分配:默认 chunk=1,动态分配的任务粒度为1;
增大 chunk 可以增大任务的粒度;
调度开销不容忽视。
guided:动态调度,chunk 大小动态缩减;
为了减少调度开销,动态分配任务的粒度逐步减小:调整策略:粒度=剩余迭代次数/线程数;
最小粒度为 chunk,默认为1。
runtime:由环境变量 OMP_SCHEDULE 确定 (上述三种之一);
auto:系统自选。
chunk:分块大小,必须是正整数。
xxxxxxxxxx9101 n=11111111;2 h=1.0/(double)n;3 pi= 0.0;4
5 6 for(i=1; i<=n;i++)7 {8 x = h * ((double)i-0.5);9 pi +=4.0* h*sqrt(1.-x*x);10 }其他工作享构造
ordered从句与ordered构造
ordered 从句:声明 for 循环中有潜在的顺序执行部分
11注意1:ordered 从句和构造必须同时存在才起作用;
注意2:ordered 区内的语句任意时刻仅由最多一个线程执行;
注意3:为了提升并行度,需要合理调整循环的 schedule 方式。
collapse从句
collapse从句:将for构造应用于多重循环的第1至n重。
涉及的循环间必须没有依赖关系;
相当于对第1至n重循环做了合并,当作了一个循环;
相当于增大外层循环次数,从而有助于schedule。
1 for(i= 0; i<10;i++){3 for(j =0;j<100;j++){4 ...5 }6 }sections构造
对非循环任务多线程并行执行。
sections 构造内由 section 划分出不同的程序段;
各个 section 程序段分别并发执行;
每个程序段由一个线程执行:
线程数等于 section 数:线程与程序段一一对应;
线程数大于 section 数:个别线程空闲;
线程数小于 section 数:个别线程执行多于一个程序段;
无法提前得知哪个线程执行哪个程序段,唯一知道的是每个程序段被执行且只被执行了一次。
xxxxxxxxxx1 {3 4 code1();5 6 code2();7 ...8 }nowait从句:去掉工作共享构造末尾的隐式栅栏同步,可以用于for、sections、single。
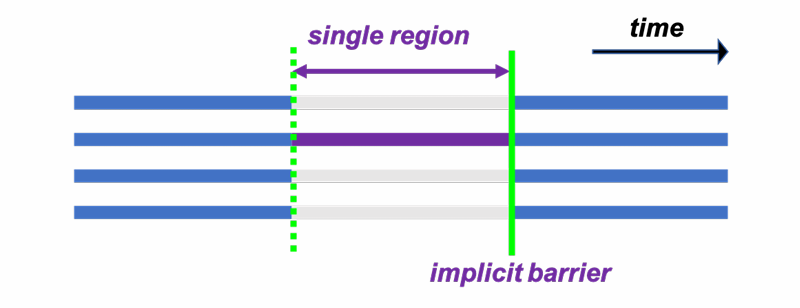
single构造
对并行区内的一段代码单线程执行
无法提前得知是哪个线程执行single标记的代码;
其他线程等待该线程执行完毕后进行同步;
一般用于处理非线程安全(threadsafe)的任务, 如I/O、对共享变量赋值等。
任务构造
OpenMP 工作共享构造的缺陷:任务必须可数
比如,下面的任务(如链表、递归等)无法支持:
只支持任务可数的情况(for循环或者 section区块);
如果不能转换为可数任务,缺乏灵活的任务处理机制。
xxxxxxxxxx1{3 ...4 while (my_pointer != NULL) {5 do_independent_work(my_pointer);6 my_pointer = my_pointer->next;7 } // End of while loop8 ...9}OpenMP的任务并行(taskparallelism) 显式定义一系列可执行的任务及其相互依赖关系,通过任务调度的方式多线程动态执行,支持任务的延迟执行(deferredexecution)。
OpenMP任务构造
定义任务:#pragma omp task[clause1 clause2]
支持的从句:
if (scalar expression)
final (scalar expression)
untied
default (shared | none)
mergeable
private (list)
firstprivate (list)
shared (list)
完成任务:
自动完成:在程序的显式或者隐式同步点;
手动完成: #pragma omp taskwait。
变量的数据域
并行区中的共享变量:在 task区中默认也为共享;
并行区中的私有变量:在 task区中默认为 firstprivate;
task 区中的其他变量:默认为私有。
xxxxxxxxxx171 uint64_t fib(int n){2 uint64_t x,y,res;3 4 if (n<2) res=n;5 else6 {7 8 x = fib(n-1);9 10 y = fib(n-2);11 12 res=x+y;13 }14 15 a[n]=res;16 return a[n];17 }线程控制
动态线程
动态线程:系统动态选择并行区的线程数(默认:一般为关闭)。
库函数: void omp_set_dynamic(int flag)
环境变量: export OMP_DYNAMIC=true
检查动态线程是否打开:int omp_get_dynamic (void)
x
1 omp_set_dynamic(flag);2 3 {4 ...5 }上述例子中:flag为0则开启了10个线程;flag不为0则开启1-10个线程(系统决定)。
嵌套并行
嵌套并行:指在并行区之内开启并行区(默认:一般为开启)。
库函数: void omp_set_nested(int flag)
环境变量1:export OMP_NESTED=true
环境变量2:export OMP_NUM_THREADS=n1,n2,n3,...
检查嵌套并行是否打开:int omp_get_nested(void)
flush构造
OpenMP 的松弛一致性(relaxed consistency):
数据不仅在内存,还在缓存(以及寄存器等)中有多份拷贝;
实际上OpenMP 的共享变量在本地缓存中并不随时更新。
flush 构造:手动更新当前线程本地缓存中的数据。
xxxxxxxxxx11 OpenMP 的一些同步操作隐含包含了 flush,比如:
并行区入口,critical/ordered 区的入口、出口;(注意:工作共享构造的入口/出口是不隐含包含 flush的)
显式、隐式的 barrier 操作等。
若确需flush,一般置于共享变量的写操作后,或读操作前; 合理的算法设计一般不需要显式的flush(因为容易出错)。
堆栈大小
除了主线程,OpenMP 的每个线程的私有变量存储空间受线程的堆栈大小控制。
OpenMP 标准并不规定具体的堆栈大小,依赖于具体实现:
Intel 编译器:默认大小一般为4MB;
gcc/gfortran 编译器:默认大小一般为 2MB。
如果超出堆栈大小,程序的行为不可控;
可以通过环境变量修改默认堆栈大小,比如:
xxxxxxxxxx21export OMP_STACKSIZE=32M 2export OMP_STACKSIZE=8192K 同步构造
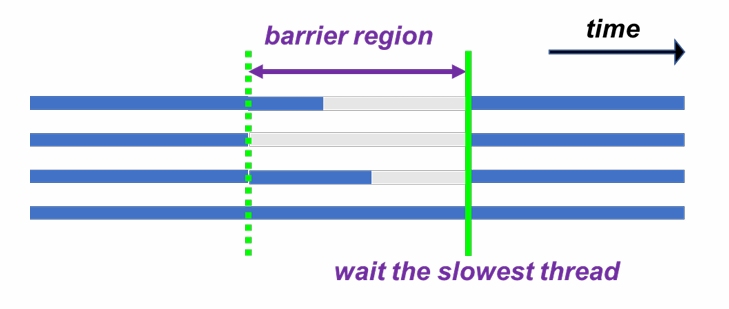
barrier构造:栅栏同步
在并行区中特定位置显式加入栅栏同步:#pragma omp barrier
single构造:有同步
对并行区内的一段代码单线程执行,有同步(可用nowait去掉)
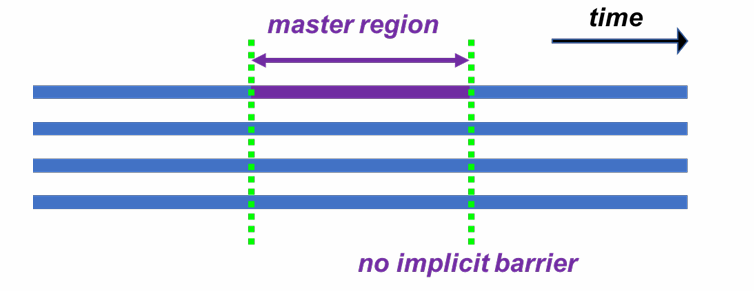
master构造:无同步
对并行区内的一段代码采用主线程执行,无同步: (可以看作是一种加上nowait的特殊版的single构造)
critical构造
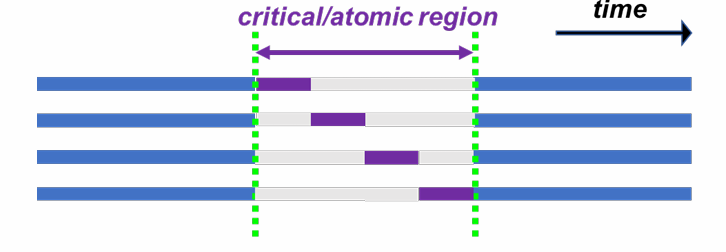
对并行区内的一段代码依次互斥执行
atomic构造
可认为是一种特殊的critical构造,对单个特定格式的语句或语 句组中某个变量进行原子操作(如对x原子操作)
xxxxxxxxxx81 something= x;3 4 x=something;5 6 x=xbinop something;7 8 {x=xbinop something;anotherthing=x;}竞争条件和线程安全
竞争条件(race condition) 指的是并行程序的执行结果具有随机性,依赖于某些事件的发生顺序,在OpenMP中竞争条件的产生往往是由于多个线程同时更新同一片内存地址空间(如共享变量);
称程序为线程安全(thread safe),一般指竞争条件可以完全避免,如I/O 操作、OS 操作、通用库函数等均有可能不是线程安全的,需要使用单线程调用;
在OpenMP 中,避免竞争条件发生的主要手段有:
使用 critical 构造;
使用 atomic 构造;
使用 reduction 从句等。
程序的遗孤
并行区的作用范围:
静态范围(static extent):并行区直接影响的代码段;
动态范围(dynamic extent):并行区间接影响的代码,例如在 并行区内被调用的函数。
遗孤(orphaning):工作共享和同步构造被放在并行区静态范围外:
如果在动态范围之内,等同于非遗孤情况;
否则,制导语句不起作用;
sections 构造不支持遗孤。
持久变量
持久(persistent) 变量:一般指生存周期为整个程序的变量数据,例如全局变量、静态变量等。
如果希望每个线程拥有自己的持久变量,并且可以随心所欲地在不同线程间传递各自持久变量的值,怎么办?
OpenMP 的线程私有型变量提供了上述机制:
threadprivate 构造提供了持久变量的私有化机制;
copyin 从句提供了将主线程的 threadprivate 变量的值传递给其他线程的机制;
copyprivate 从句提供了将某线程的 threadprivate 变量的值广播给其他线程的机制
threadprivate 构造
threadprivate 构造:将持久变量置为线程私有类型
对全局变量:必须置于全局变量声明列表之后并在被首次使用之前,否则不起作用;
对静态变量:必须置于 static 变量声明列表之后并在被首次使用之前,否则不起作用;
注意:与 private 类型变量的最大差别是,threadprivate 型变量的值可以跨并行区有效(前提是动态线程关闭,并且每个并行区线程数一致)。
全局或静态变量的传递与广播
copyin从句用于将主线程的threadprivate变量的值传递给其他线程,仅能用于并行区构造的初始化:
xxxxxxxxxx11{...} copyprivate从句用于将某线程的threadprivate变量的值广播 给其他线程,仅能用于single构造,并在其出口处起作用:
21 {...}向量化
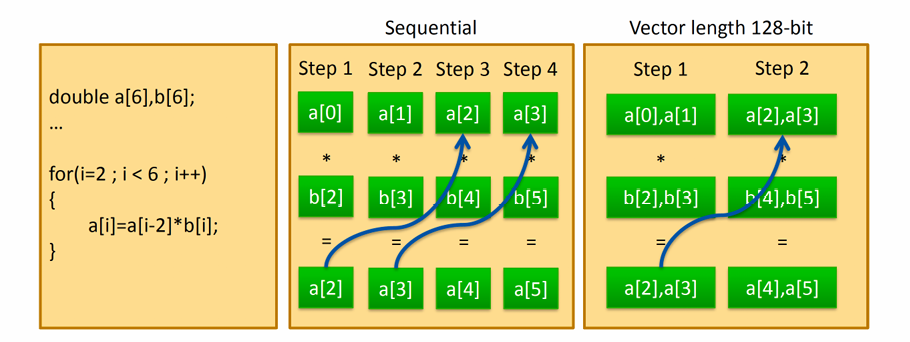
大多数处理器均提供具有SIMD向量化功能的硬件指令,这些SIMD 指令一般作用于向量化寄存器中,通过SIMD 向量化,可以加速计算。
OpenFOAM的simd构造
OpenFOAM提供simd构造对循环进行向量化计算
collapse 从句:先对多重循环进行合并,然后进行向量化
linear 从句:列出与迭代变量有线性关系的变量
aligned 从句:列出内存地址对齐的数组或指针
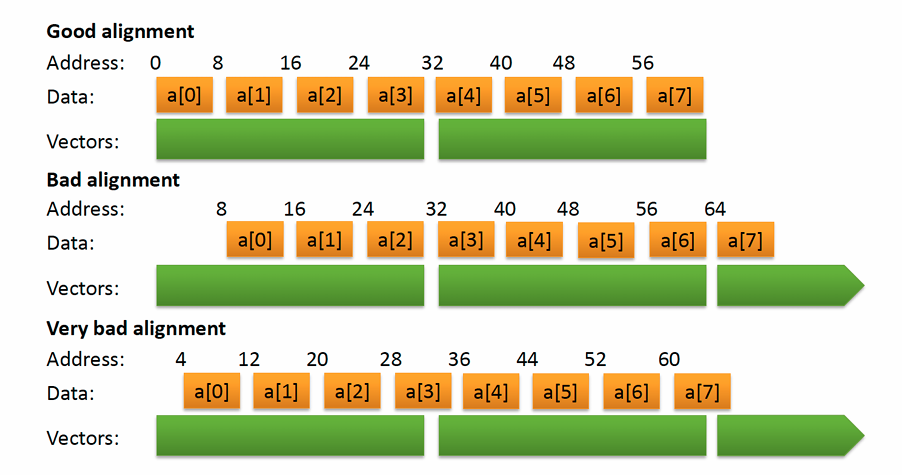
safelen 从句:给出没有循环间数据依赖的最大步长
进行向量化时需要注意不要破坏循环携带的数据依赖,simd 构造向量化的循环仍然按照顺序依次执行
SIMD 向量化的循环中,如果有外部函数调用,有可能带来严重的性能瓶颈,因为此时函数的执行是完全串行的。
declare simd构造
declare simd构造:用于提示编译器根据需要生成一个至多个具有SIMD向量化功能的函数。
11linear从句:列出与迭代变量有线性关系的变量
aligned从句:列出内存地址对齐的变量
uniform从句:列出不变量
simdlen从句:给出需要同时向量化计算的变量个数
inbranch/notinbranch从句:声明在/不在分支判断中被调用
编译器的自动向量化
事实上,不少编译器都提供了较为不错的自动向量化功能:
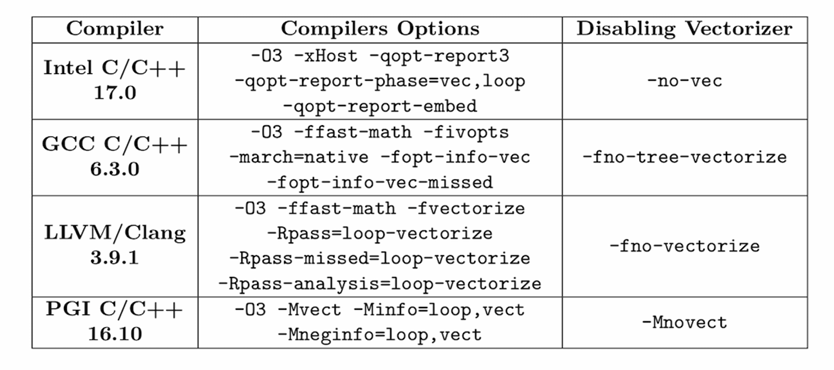
从句汇总
根据上述所有内容,我们作出从句汇总如下:
